We’re proud to announce that MergeStat has raised over $1.2m in pre-seed funding led by OSS Capital, with participation from Caffeinated Capital and prominent angel investors.
At MergeStat, our mission is to enable operational analytics for software engineering teams via powerful, open-source tooling and systems.
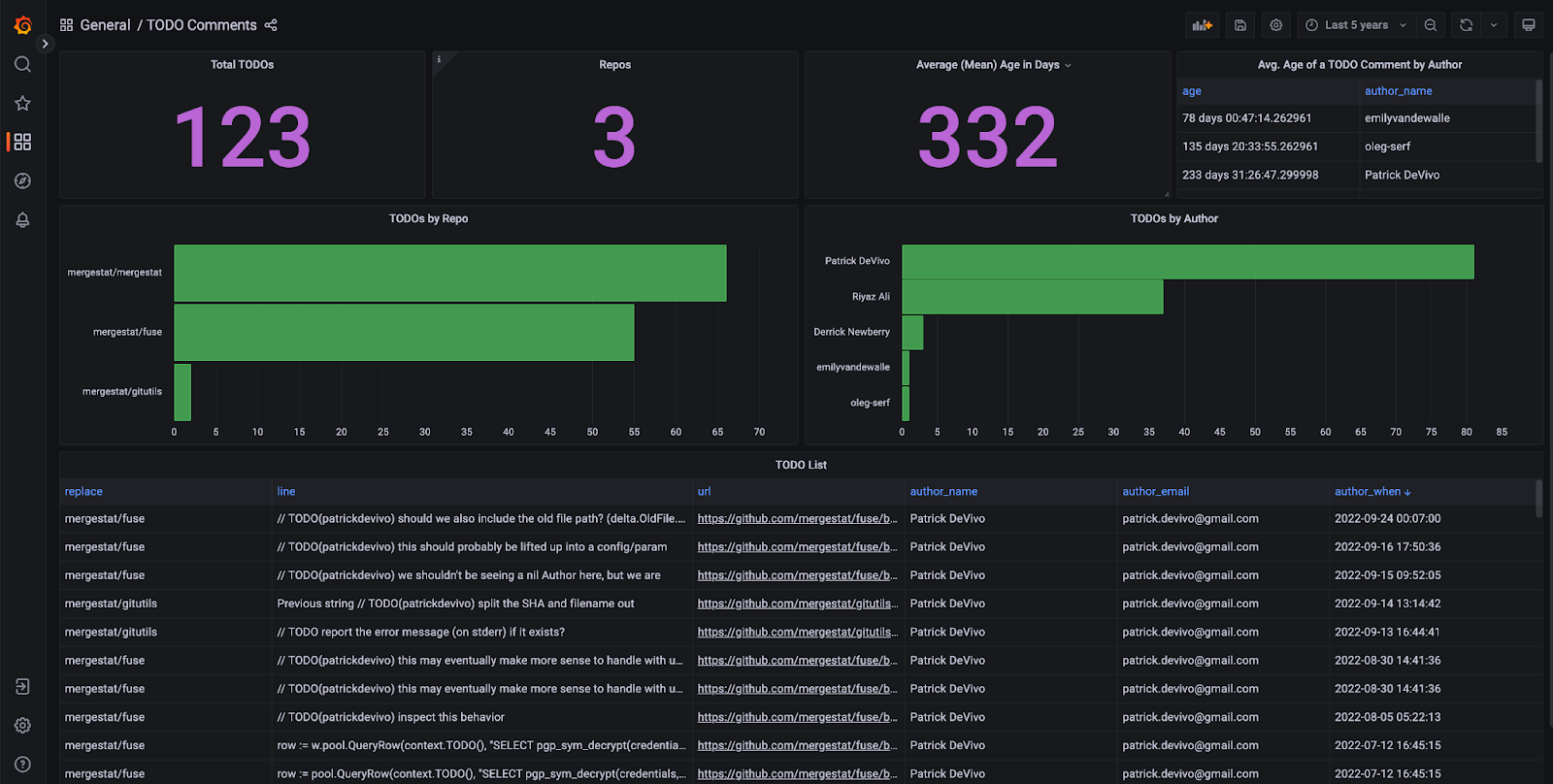
We believe there is tremendous value in connecting SQL with the systems used to build and ship software. Engineering organizations are often “black boxes” driven by intuition and gut-feel decisions. By enabling access to the processes and artifacts of software engineering as data, MergeStat helps organizations become data-driven in the ways most relevant to their needs.
Our PostgreSQL approach is based on applying SQL to the data sources involved in building and shipping software. SQL not only grants the ability to ask adhoc questions, but also brings compatibility with many BI, visualization, and data platforms.
We’re working with a variety of organizations using MergeStat to answer questions about the software-development-lifecycle, in the tools they prefer. To date, we’ve worked with teams using our SQL approach to answer questions around:
- Audit and compliance
- Code and dependency version sprawl
- Engineering metrics and transparency (DORA metrics)
- Code pattern monitoring and reporting
- Developer on-boarding
- Vulnerability reporting
- …and more
“MergeStat is bringing the lingua franca of data to code: applying SQL to the modern SDLC will unlock tremendous value for all software developers. We are greatly honored to partner with Patrick DeVivo on this important mission!”
– Joseph Jacks, Founder and General Partner at OSS Capital
Over the past year, MergeStat has grown into an amazing team with a growing open-source presence. We’re very excited for our next chapter, as we begin working with more organizations looking to answer questions about how their engineering teams operate.
Investors
- OSS Capital (Joseph Jacks)
- Caffeinated Capital (Charlie Marsh)
- Zac and Jacob Smith
- Bruce Wang
- Justin Dignelli
- Rez Khan
- Elliott Rapaport
- Josue Lopez
- …and others